
Для понимания и реализации этот алгоритм — простейший, но эффективен он лишь для небольших массивов. Сложность алгоритма: O(n²).
*-Нравится статья? Кликни по рекламе! :)
Расположим массив сверху вниз, от нулевого элемента - к последнему.
Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.
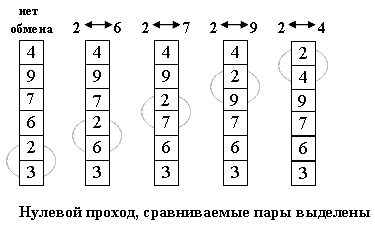
После нулевого прохода по массиву "вверху" оказывается самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент поднимается на правильную позицию.
Делаем проходы по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию.
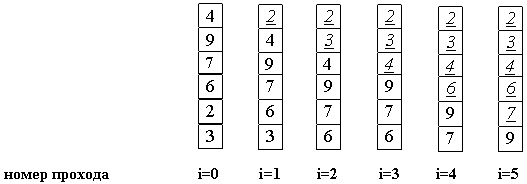
Среднее число сравнений и обменов имеют квадратичный порядок роста: O(n2), отсюда можно заключить, что алгоритм пузырька очень медленен и малоэффективен.
Тем не менее, у него есть громадный плюс: он прост и его можно по-всякому улучшать.
Тем не менее, у него есть громадный плюс: он прост и его можно по-всякому улучшать.
Чем мы сейчас и займемся:
- Во-первых, рассмотрим ситуацию, когда на каком-либо из проходов не произошло ни одного обмена. Что это значит ?Это значит, что все пары расположены в правильном порядке, так что массив уже отсортирован. И продолжать процесс не имеет смысла(особенно, если массив был отсортирован с самого начала !).Итак, первое улучшение алгоритма заключается в запоминании, производился ли на данном проходе какой-либо обмен. Если нет - алгоритм заканчивает работу.
- Процесс улучшения можно продолжить, если запоминать не только сам факт обмена, но и индекс последнего обмена k. Действительно: все пары соседих элементов с индексами, меньшими k, уже расположены в нужном порядке. Дальнейшие проходы можно заканчивать на индексе k, вместо того чтобы двигаться до установленной заранее верхней границы i.
- Качественно другое улучшение алгоритма можно получить из следующего наблюдения. Хотя легкий пузырек снизу поднимется наверх за один проход, тяжелые пузырьки опускаются со минимальной скоростью: один шаг за итерацию. Так что массив 2 3 4 5 6 1 будет отсортирован за 1 проход, а сортировка последовательности 6 1 2 3 4 5 потребует 5 проходов.Чтобы избежать подобного эффекта, можно менять направление следующих один за другим проходов.
Получившийся алгоритм иногда называют "шейкер-сортировкой".
Лучший случай для этой сортировки — отсортированный массив (О(n)), худший — отсортированный в обратном порядке (O(n²)).
Лучший случай для этой сортировки — отсортированный массив (О(n)), худший — отсортированный в обратном порядке (O(n²)).
def shakerSort(a):
#lb, ub границы неотсортированной части массива
k= ub = len(a)-1
lb=1
while ( lb < ub ):
# проход сверху вниз
for j in xrange (ub, lb-1, -1):
if a[j-1] > a[j]:
a[j-1], a[j] = a[j], a[j-1]
k=j
lb = k
# проход снизу вверх
for j in xrange (lb, ub+1):
if a[j-1] > a[j]:
a[j-1], a[j] = a[j], a[j-1]
k=j
ub = k
return a
Насколько описанные изменения повлияли на эффективность метода ? Среднее количество сравнений, хоть и уменьшилось, но остается O(n2), в то время как число обменов не поменялось вообще никак. Среднее(оно же худшее) количество операций остается квадратичным.
Дополнительная память, очевидно, не требуется. Поведение усовершенствованного (но не начального) метода довольно естественное, почти отсортированный массив будет отсортирован намного быстрее случайного. Сортировка пузырьком устойчива, однако шейкер-сортировка утрачивает это качество.
На практике метод пузырька, даже с улучшениями, работает, увы, слишком медленно. А потому - почти не применяется.
Так же мы создавали сортировку пузырьком, когда рассматривали связный список, но он сортирует 5000 значений 183 сек, в то время, как shaker_sort 3.6 сек.
Интересная статья, не совсем про сортировку и Python, но в тему)
Вычисление времени выполнения
Все операторы присваивания, как и проверки if имеют некоторое постоянное время выполнения О(1). Все операторы в каждом из циклов, в среднем, выполняются n-i раз. А по правилу сложения времен 2n-2i(т.к. 2 цикла). Цикл while в среднем выполняется (n-1)/2 раз. И если мы напишем формулу суммы сократив заранее 2-ки, получим среднее выражение
 Тем самым мы показали, что данный алгоритм имеет порядок роста O(n2)
Тем самым мы показали, что данный алгоритм имеет порядок роста O(n2)
Используемая литература:Так же мы создавали сортировку пузырьком, когда рассматривали связный список, но он сортирует 5000 значений 183 сек, в то время, как shaker_sort 3.6 сек.
Интересная статья, не совсем про сортировку и Python, но в тему)
Вычисление времени выполнения
Все операторы присваивания, как и проверки if имеют некоторое постоянное время выполнения О(1). Все операторы в каждом из циклов, в среднем, выполняются n-i раз. А по правилу сложения времен 2n-2i(т.к. 2 цикла). Цикл while в среднем выполняется (n-1)/2 раз. И если мы напишем формулу суммы сократив заранее 2-ки, получим среднее выражение
Очень такое хорошее объяснение пузырьковой сортировки! Я думаю новичкам понравится!
ОтветитьУдалитьСпасибо за позитивное мнение) Очень рад, что кто-то готов высказаться, а то в большинстве постов тишина. Либо всё хорошо и понятно, либо полный бред.
ОтветитьУдалитьРаньше об алгоритмах сортировки знал только названия самых популярных. Ну а теперь я стал немного круче)
ОтветитьУдалитьРад, что помогает) Завтра выложу про быструю сортировку Хоара, с эксклюзивным алгоритмом))
ОтветитьУдалитьПавел, спасибо Вам за Ваш труд!
ОтветитьУдалитьОгромное спасибо.
ОтветитьУдалить