
Ищем похожих пользователей
Собрав данные о том, что людям нравится, нужно как-то определить, насколько их вкусы схожи. Для этого каждый человек сравнивается со всеми другими и вычисляется коэффициент подобия (или оценка подобия). Для этого есть несколько способов, я расскажу о двух из них: евклидовом расстоянии и коэффициенте корреляции Пирсона. Примеры будем разбирать, отталкиваясь от задачи поиска схожести вкусов людей к фильмам, исходя из их оценок.
Оценка по евклидову расстоянию
Один из самых простых способов вычисления оценки подобия – это евклидово расстояние. В этом случае предметы, которые люди оценивали сообща, представляются в виде координатных осей. Теперь в этой системе координат можно расположить точки, соответствующие людям, и посмотреть, насколько они оказались близки.

Я думаю, некоторые из вас вспомнили формулу нахождения расстояния в пространстве между 2мя точками. Да-да) Это оно и есть, и не важно, сколь мерно наше пространство, формула легко модифицируется, добавлением квадратов разностей других координат.

Расстояние, вычисленное по этой формуле, будет тем меньше, чем больше сходства между людьми. Однако нам нужна функция, значение которой тем больше, чем люди более похожи друг на друга. Этого можно добиться, добавив к вычисленному расстоянию 1 (чтобы никогда не делить на 0) и взяв обратную величину.
Коэффициент корреляции Пирсона
Чуть более сложный способ определить степень схожести интересов людей дает коэффициент корреляции Пирсона. Коэффициент корреляции – это мера того, насколько хорошо два набора данных ложатся на прямую. Формула сложнее, чем для вычисления евклидова расстояния, но она дает лучшие результаты, когда данные плохо нормализованы, например если некоторый человек устойчиво выставляет фильмам более низкие оценки, чем в среднем.
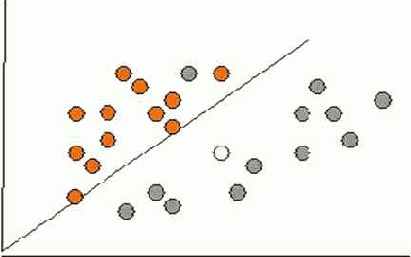
На картинке изображена прямая линия. Она называется линией наилучшего приближения, поскольку проходит настолько близко ко всем точкам на диаграмме, насколько возможно. В данном случае оценки одного человека, являются абсциссами точек, а оценки другого ординатами. Если бы оба человека выставили всем фильмам одинаковые оценки, то эта линия оказалась бы диагональной и прошла бы через все точки. В этом случае получилась бы идеальная корреляция с коэффициентом 1.

У коэффициента корреляции Пирсона есть одно интересное свойство, которое можно наблюдать на рисунке – он корректирует обесценивание оценок! Что я имею ввиду? А то, что представьте. 2 человека сравнивают цены и 2й всегда ставит на 1-2 бала ниже(ну пессимист он эдакий)))) А теперь начертите прямую в голове(или листочке)) и увидите, что прямая все равно проходит почти по диагонали, а значит считает, что они могут понравиться друг-другу (сугубо с точки зрения вкусов к фильмам...а может и нет))))!
Проблема нормализации
Но также у данного коэффициента есть одна плохая сторона. Он рассчитан наприменение к данным с нормальным распределением. А что будет, если какой то пользователь ставит всем фильмам одинаковые оценки? Можете подставить в формулу, например за место X и увидите, что в таком случае и знаменатель и числитель вырождаются в 0! Ведь это не правильно! Бывает так, что вы смотрели вместе 10 великолепных картин и он и вы ставили только 10ки и получается, что заместо коэффициента=1 мы получим 0! Геометрически такое поведение можно объяснить вырождением прямой в точку. Не знаю, как эта проблема решается правильно, а я предлагаю сделать искусственную нормализацию распределения оценок. Каким образом, а просто добавим и тому и другому оценку за несуществующий фильм отличную от тех, что они ставят, но одинаковые между собой. Причем опытным путем было замечено. что чем оценка меньше, тем меньше она влияет на коэффициент.Какой оценкой подобия воспользоваться
Я ознакомил вас с двумя разными метриками, но есть и много других способов измерить подобие двух наборов данных. Какой из них оптимален – зависит от конкретного приложения. Имеет смысл попробовать и коэффициент Пирсона, и евклидово расстояние, и другие методы, а потом посмотреть, какой дает наилучшие результаты.
Для вычисления подобия можно брать и различные другие функции, например коэффициент Жаккарда или манхэттенское расстояние, при условии что у них такая же сигнатура и возвращаемое значение с плавающей точкой тем больше, чем выше сходство.
Практика Евклида
Все читали предыдущую статью? Если да то база готова и туда пишутся данные(у меня уже 12000 пользователей Ж) И пока их не много, можно запустить секретный скрипт прям в postgre и получить результатик) Если скрипт запустить как есть, то он будет сравнивать всех со всеми в поисках идеальных пар) Если же закомментить строку 7 и наоборот раскомментить 9(подставив нужный user_id) будем искать идеал только для кого то конкретного (например для себя любимого))))
select v1.user_id, v2.user_id, 1/(1+(|/sum((v1.vote-v2.vote)^2))),--евклидово не взвешенное расстояние count(1)--кол-во общих фильмов(вес для ф-ии) from votes v1 join votes v2 on v1.film_id=v2.film_id and v1.user_id < v2.user_id --гениально и просто убираем дубли self джойна)) where v1.user_id <> v2.user_id --and v2.user_id=113 group by v1.user_id, v2.user_id order by 1/(1+(|/sum((v1.vote-v2.vote)^2))) desc, count(1) desc
У меня он выдал 197184 результата за 703882 ms. Короче чуть не уснул и это тысячах на 6 юзверях, но если вы подождете, то будете вознаграждены) Поиск же для кого-то конкретного проходит на ура и в миллисекунды :) Нужно сразу сказать, что здесь ф-ия евклида вычисляется для мнений по одному и тому же фильму и по этому эта оценка не взвешенная! Например есть люди, которые идеально друг другу подходят (т.е. 1 выдало ;) и все потому, что у них всего 1 общий фильм из 1000 и каждый поставил по 2 балла)))) Не думаю, что таких людей можно рекомендовать друг-дружке, как братьев по вкусу))) Поэтому результаты нужно взвесть и чем больше общих фильмов оценено - тем лучше(если что count(1) именно это и считает)
#Для ярых питонистов плюющих в души sql ворую код
# на вход prefs - словарь {чел1:{фильм1:оценка1, фильм2:оценка2,...}, чел2:{фильм?:оценка?,...}}
# кто-то может расширить ф-ию сравнения не 2х челов, а N :)
from math import sqrt
def sim_distance(prefs):
person1, person2 = prefs.keys()
# Получаем список фильмов, оцененных обоими
si={item:1 for item in prefs[person1] if item in prefs[person2]}
if si:
# сложить квадраты разностей оценок
sum_of_squares=sum([pow(prefs[person1][item]-prefs[person2][item],2)
for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sqrt(sum_of_squares))#sqrt добавил сам, кажись автор забыл)
# если нет ни одной общей оценки, return 0
return 0
Практика Пирсона
Прочитали описание коэффициента чуть выше? Тогда поехали)
Для начала скрипт sql, без искусственной нормализации!!!
select
v1.user_id, v2.user_id,
case when (sum(v1.vote^2)-(sum(v1.vote)^2)/count(1)::float)*(sum(v2.vote^2)-(sum(v2.vote)^2)/count(1)::float) <> 0
then
(sum(v1.vote*v2.vote)-(sum(v1.vote)*sum(v2.vote))/count(1)::float)/(|/((sum(v1.vote^2)-(sum(v1.vote)^2)/count(1)::float)*(sum(v2.vote^2)-(sum(v2.vote)^2)/count(1)::float)))
else
0
end,
count(1)--кол-во общих фильмов(вес для ф-ии)
from votes v1
join votes v2 on v1.film_id=v2.film_id
where v1.user_id <> v2.user_id
and v2.user_id=113 --ищем для конкретного пользователя(так быстрее)
group by v1.user_id, v2.user_id
order by
case when (sum(v1.vote^2)-(sum(v1.vote)^2)/count(1)::float)*(sum(v2.vote^2)-(sum(v2.vote)^2)/count(1)::float) <> 0
then
(sum(v1.vote*v2.vote)-(sum(v1.vote)*sum(v2.vote))/count(1)::float)/(|/((sum(v1.vote^2)-(sum(v1.vote)^2)/count(1)::float)*(sum(v2.vote^2)-(sum(v2.vote)^2)/count(1)::float)))
else
0
end
desc,
count(1) desc
Снова сворую чужую функцию для Питонистов, но теперь с решением проблемы нормализации:
#На вход тоже, что и раньше
def sim_pearson(prefs):
#вспомогательная ф-ия для удаления повторяющейся оценки
def rem_vote(votes, choice_list):
vote_for_rem = votes.pop()
if vote_for_rem in choice_list:
choice_list.remove(vote_for_rem)
return choice_list#это не обязательно, т.к. элемент и так удален по ссылке, но явное лучше не явного)))
# Получаем список фильмов, оцененных обоими
si={}
p1, p2 = prefs.keys()
for item in prefs[p1]:
if item in prefs[p2]: si[item]=1
#делаем нормализацию, если кто-то ставит одинаковые оценки всем фильмам
#опытным путем пришел к тому, что чем меньше число добавляем, тем меньше его влияние
votes1 = set([prefs[p1][it] for it in si])
votes2 = set([prefs[p2][it] for it in si])
if len(votes1) == 1 or len(votes2) == 1:
choice_list = range(1, 4)#список возможных оценок от 1 до 4
#удаляем повторяющиеся оценки
if len(votes1) == 1:
choice_list = rem_vote(votes1, choice_list)
if len(votes2) == 1:
choice_list = rem_vote(votes2, choice_list)
it = 0#id несуществующего фильма
si[it] = 1#говорим, что оба оценивали фильм с этим id
rand_vote = random.choice(choice_list)
prefs[p1][it] = prefs[p2][it] = rand_vote
##############################
# Число общих фильмов
n=len(si)
# Если общих фильмов нет
if n==0: return 0
# Суммы всех предпочтений
sum1=sum([prefs[p1][it] for it in si])
sum2=sum([prefs[p2][it] for it in si])
# Суммы квадратов предпочтений
sum1Sq=sum([pow(prefs[p1][it],2) for it in si])
sum2Sq=sum([pow(prefs[p2][it],2) for it in si])
# Сумма произведений
pSum=sum([prefs[p1][it]*prefs[p2][it] for it in si])
# Вычисляем коэффициент
num=pSum-(sum1*sum2/n)
den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
if den==0: return 0
r=num/den
return r
Немного о чувствительности критериев
К слову о том, каким критерием пользоваться, не стоит забывать об их чувствительности к деградации. О чем я? Например я сравнил себя с другим пользователем и оказалось, что мы оценили 5 общих фильмов. Причем он всем поставил 10 баллов, а я двум 9ки. Таким образом я потерял 2/50 не взвешенных баллов от 1. Но если мы вычислим реальные коэффициенты, то получим следующие результаты: Евклид=0.414, Пирса=0.981. Таким образом видно, что ф-ия Евклида очень чувствительна при малом кол-ве общих оценок.
Комментариев нет:
Отправить комментарий